💻 Architecture Informatique Matérielle - S5
Année: 2022-2023 (Semestre 5)
Crédits: 3 ECTS
Type: Informatique / Architecture des Systèmes
PART A: PRÉSENTATION GÉNÉRALE
Objectifs du cours
Le cours “Architecture Informatique Matérielle” fournit une compréhension approfondie de l’organisation et du fonctionnement des systèmes informatiques au niveau matériel. Il couvre l’ensemble de la hiérarchie mémoire, de l’architecture des processeurs, et des mécanismes d’optimisation des performances. Ce cours est fondamental pour comprendre comment le matériel influence les performances logicielles et pour concevoir des systèmes embarqués efficaces.
Compétences visées
- Maîtriser les concepts d’architecture des processeurs (RISC, pipeline, unités fonctionnelles)
- Comprendre la hiérarchie mémoire (mémoire physique, virtuelle, caches)
- Analyser les performances des systèmes informatiques
- Programmer en assembleur MIPS pour le bas niveau
- Optimiser le code en fonction de l’architecture matérielle
- Comprendre les mécanismes de pagination et de gestion mémoire
Organisation
- Volume horaire: 30h (CM: 18h, TD: 12h)
- Évaluation: Examen écrit + TDs notés + TP assembleur
- Semestre: 5 (2022-2023)
- Prérequis: Logique séquentielle, systèmes numériques
PART B: EXPÉRIENCE, CONTEXTE ET FONCTION
Contenu pédagogique
1. Introduction Générale aux Architectures
Concepts fondamentaux:
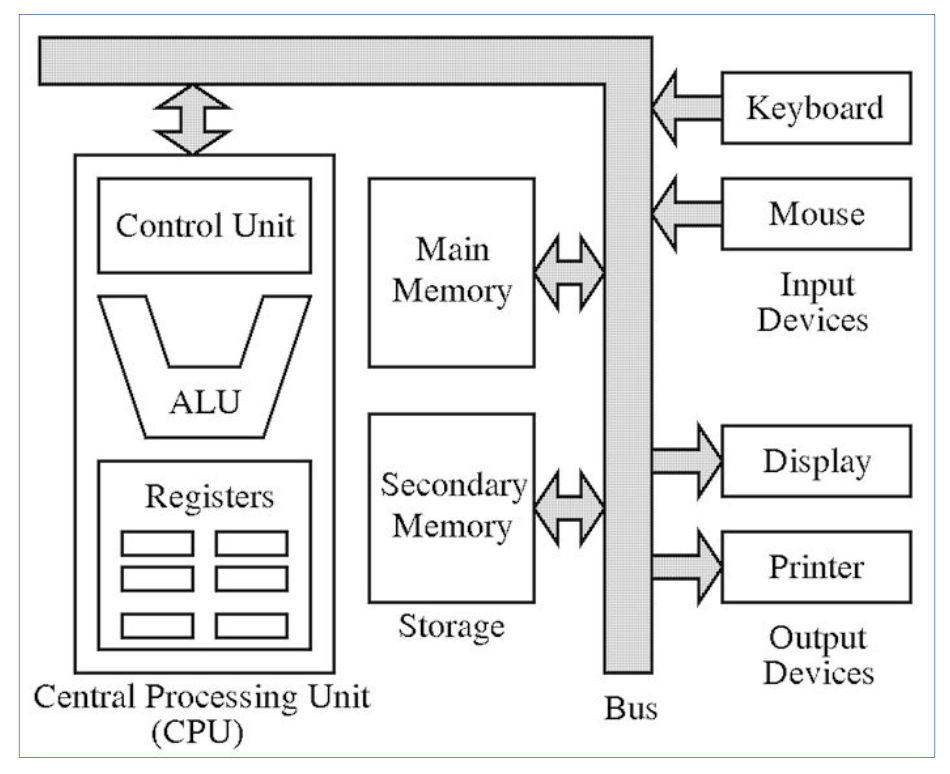
- Architecture de Von Neumann vs Harvard
- Modèle de Von Neumann: mémoire unique pour données et instructions
- Architecture Harvard: séparation physique instructions/données
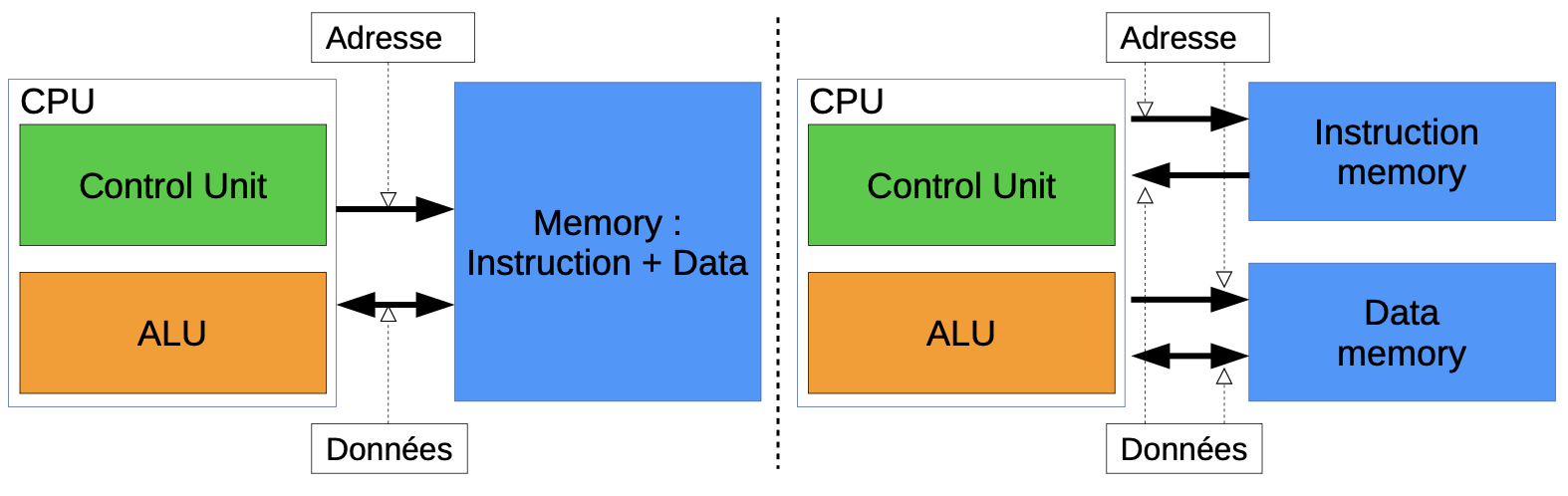
- Bus système: adresses, données, contrôle
- Cycle d’exécution: Fetch-Decode-Execute
Évolution historique:
- Des premiers ordinateurs aux architectures modernes
- Loi de Moore et ses limites actuelles
- Passage du monoprocesseur au multiprocesseur
- Architectures RISC (Reduced Instruction Set Computer) vs CISC (Complex)
Mesure de performances:
- CPI (Cycles Per Instruction)
- MIPS (Millions d’Instructions Per Second)
- Temps d’exécution CPU
- Benchmark et profiling
Supports de cours: Introduction générale aux architectures (PDF)
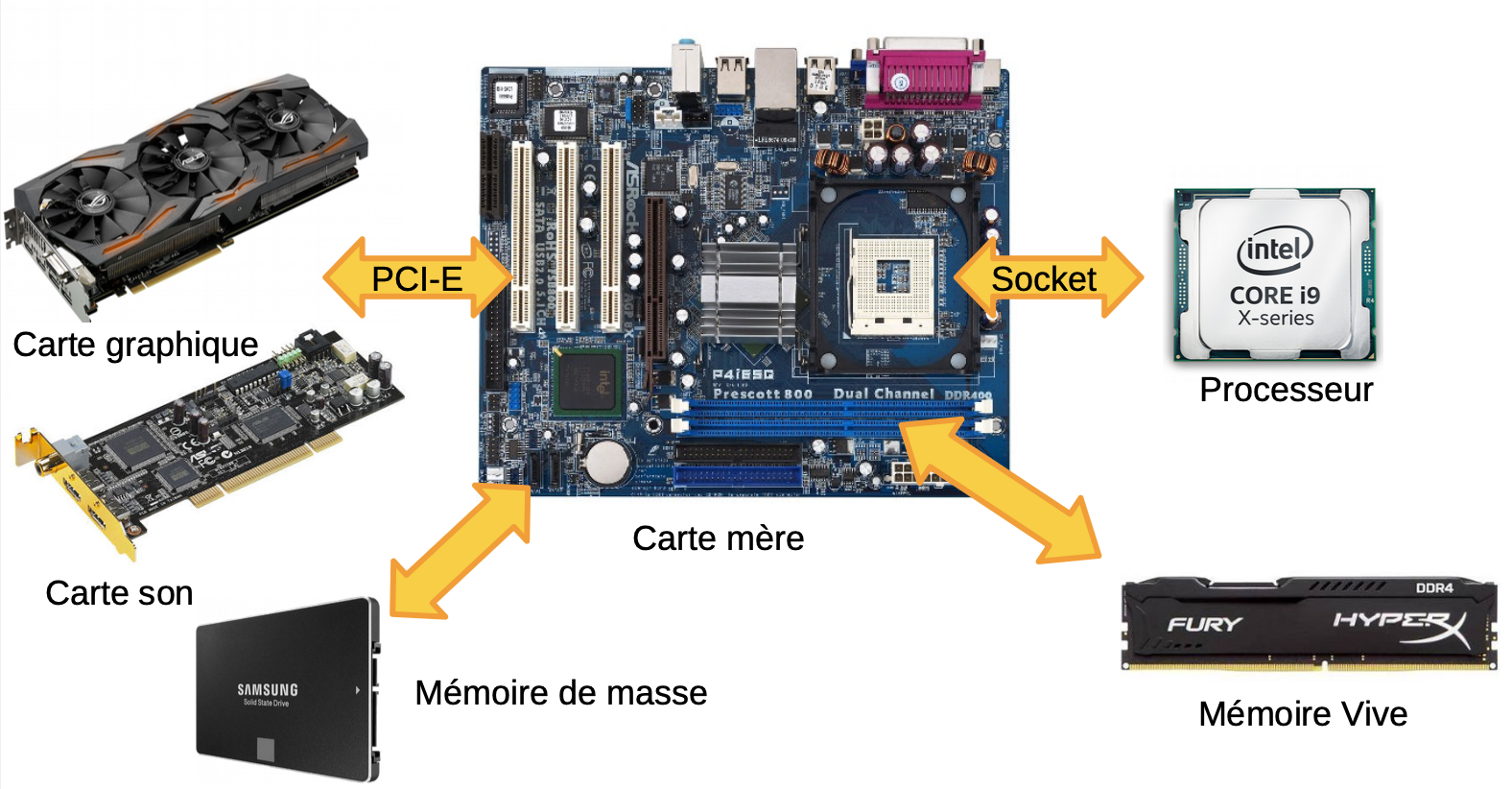
2. Mémoire Physique

Figure : Architecture Von Neumann - Modèle classique avec bus partagés
Organisation mémoire:
- Hiérarchie mémoire: registres → cache → RAM → disque
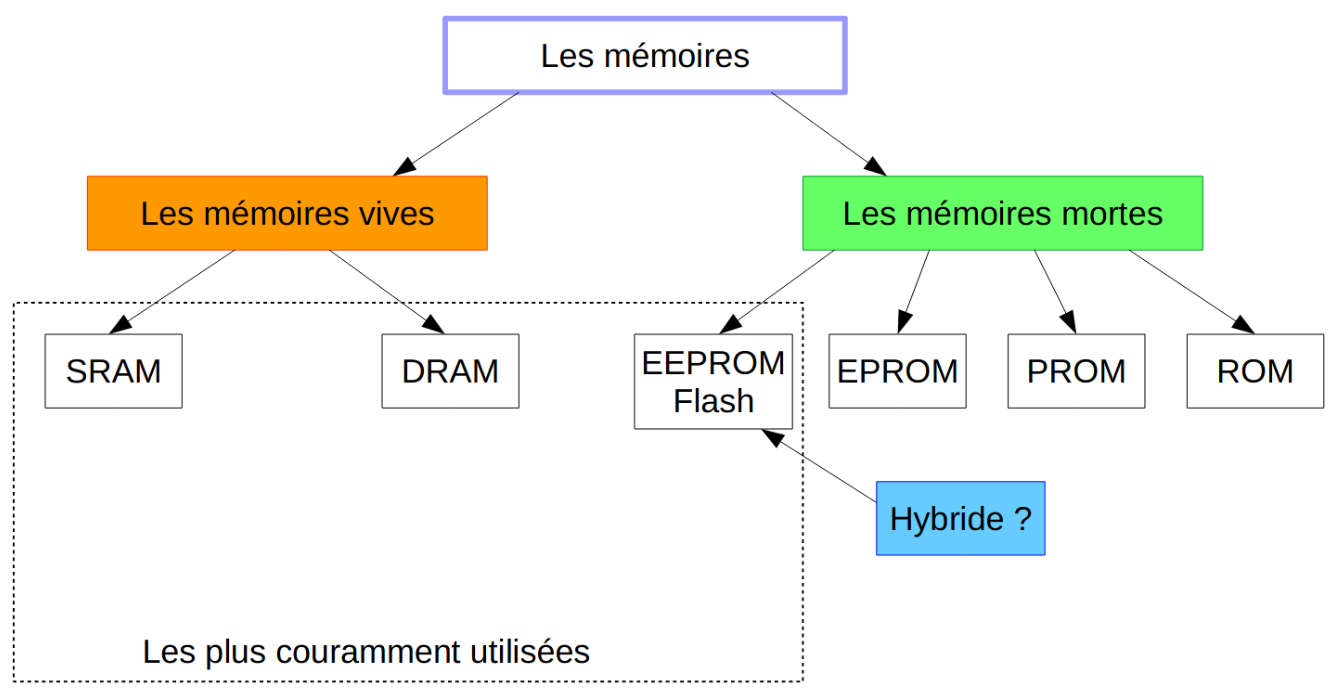
- Technologies mémoire: SRAM, DRAM, ROM, Flash
- Temps d’accès et bande passante
- Principe de localité (temporelle et spatiale)
Adressage mémoire:
- Espace d’adressage linéaire
- Adressage par mot vs par octet (byte-addressable)
- Alignement mémoire et padding
- Endianness (big-endian vs little-endian)
Organisation des données:
Exemple d'organisation mémoire 32 bits:
Adresse | Contenu (hex)
-----------|-----------------
0x00000000 | 0xAABBCCDD
0x00000004 | 0x11223344
0x00000008 | 0xFFFF0000
Supports de cours: Mémoire physique (PDF)
3. Mémoire Virtuelle
Concepts de virtualisation:
- Séparation adresse virtuelle / adresse physique
- Espace d’adressage par processus
- Protection mémoire et isolation
- Partage de mémoire entre processus
Mécanisme de pagination:
- Pages virtuelles et cadres physiques (frames)
- Taille de page typique: 4 KB, 2 MB (large pages)
- Table des pages (page table)
- TLB (Translation Lookaside Buffer): cache pour traductions
Formules de traduction:
Adresse virtuelle = Numéro de page virtuelle + Offset
Adresse physique = Numéro de cadre physique + Offset
Exemple avec pages de 4 KB (2^12 octets):
Adresse virtuelle: 32 bits
- 20 bits: numéro de page (2^20 pages)
- 12 bits: offset dans la page (4096 octets)
Gestion des défauts de page:
- Page fault (défaut de page)
- Algorithmes de remplacement: LRU, FIFO, Clock
- Swapping et pagination à la demande
- Working set et thrashing
Table des pages multi-niveaux:
- Table des pages sur 2 niveaux (x86)
- Table des pages sur 3/4 niveaux (x86-64)
- Réduction de l’espace mémoire pour les tables
- Pagination inverse
Supports de cours: Mémoire virtuelle (PDF)
4. Mémoires Caches
Principe du cache:
- Cache situé entre CPU et RAM
- Exploite la localité spatiale et temporelle
- Réduction du temps d’accès moyen
- Hiérarchie: L1 (le plus rapide), L2, L3
Organisation du cache:
Cache à correspondance directe (direct-mapped):
Adresse mémoire décomposée en:
Tag | Index | Offset
Exemple: cache 16 KB, lignes de 64 octets
Offset: 6 bits (64 = 2^6)
Index: 8 bits (256 lignes)
Tag: 18 bits (pour adresse 32 bits)
Cache associatif par ensemble (set-associative):
- N-way set-associative (2-way, 4-way, 8-way)
- Compromis entre direct-mapped et fully associative
- Politique de remplacement: LRU, Random, FIFO
Formules de performances:
Temps d'accès moyen = Hit_time + Miss_rate × Miss_penalty
Taux de hit (hit rate) = Nombre de hits / Nombre total d'accès
Taux de miss (miss rate) = 1 - Hit rate
Exemple:
Hit time = 1 cycle
Miss penalty = 100 cycles
Miss rate = 2%
Temps moyen = 1 + 0.02 × 100 = 3 cycles
Types de miss:
- Compulsory miss (cold miss): premier accès
- Capacity miss: cache trop petit
- Conflict miss: collision dans direct-mapped
Cohérence de cache:
- Problème en multiprocesseur
- Protocoles MESI, MOESI
- Write-through vs write-back
- Invalidation vs mise à jour
Supports de cours: Les caches (PDF)
5. Architecture du Processeur
Processeur RISC (MIPS):
- Jeu d’instructions réduit et régulier
- Instructions de taille fixe (32 bits)
- Load/Store architecture
- Pipeline efficace
Registres MIPS:
$zero ($0): toujours 0
$at ($1): réservé assembleur
$v0-$v1 ($2-$3): valeurs de retour
$a0-$a3 ($4-$7): arguments de fonction
$t0-$t9 ($8-$15, $24-$25): temporaires
$s0-$s7 ($16-$23): sauvegardés
$k0-$k1 ($26-$27): réservés OS
$gp ($28): pointeur global
$sp ($29): pointeur de pile
$fp ($30): pointeur de cadre
$ra ($31): adresse de retour
Formats d’instructions:
Format R (Register): opérations arithmétiques/logiques
| op (6) | rs (5) | rt (5) | rd (5) | shamt (5) | funct (6) |
Exemple: add $13, $11, $12
Format I (Immediate): load/store, branches, constantes
| op (6) | rs (5) | rt (5) | immediate (16) |
Exemple: addi $10, $zero, 53
Format J (Jump): sauts inconditionnels
| op (6) | address (26) |
Exemple: j add_32bits
Pipeline du processeur:
- IF (Instruction Fetch): chargement instruction
- ID (Instruction Decode): décodage et lecture registres
- EX (Execute): exécution ALU
- MEM (Memory): accès mémoire (load/store)
- WB (Write Back): écriture résultat dans registre
Aléas de pipeline (hazards):
- Aléas de données: RAW (Read After Write), WAR, WAW
- Aléas de contrôle: branches et sauts
- Aléas structurels: conflits de ressources
Solutions aux aléas:
- Forwarding (court-circuit)
- Stall (bulles dans le pipeline)
- Branch prediction (prédiction de branchement)
- Delayed branch
Supports de cours: Architecture du processeur (PDF) —
PART C: ASPECTS TECHNIQUES
Cette section présente les éléments techniques appris à travers les TPs et exercices pratiques.
Programmation Assembleur MIPS
TP1: Addition 32 bits et Conversion de Temps
Code assembleur réalisé:
# Initialisation des variables
addi $10, $zero, 53 # Secondes = 53
addi $1, $zero, 27 # Minutes = 27
addi $2, $zero, 3 # Heures = 3
j add_32bits # Saut vers fonction addition
# Conversion temps en secondes totales
conv_secondes:
addi $4, $zero, 3600 # $4 = 3600 (secondes/heure)
addi $5, $zero, 60 # $5 = 60 (secondes/minute)
mul $6, $2, $4 # $6 = heures × 3600
mul $7, $1, $5 # $7 = minutes × 60
add $8, $7, $6 # $8 = (heures×3600) + (minutes×60)
add $9, $8, $10 # $9 = total + secondes
# Addition 32 bits avec détection de dépassement
add_32bits:
lw $11, var # Charger variable a
lw $12, var # Charger variable b
addu $13, $12, $11 # c = a + b (addition non signée)
and $14, $11, $12 # e = a AND b (retenue entrante)
xor $15, $11, $12 # x = a XOR b (somme sans retenue)
not $18, $13 # Inversion de c
and $16, $18, $15 # x AND (NOT c)
or $17, $16, $14 # Calcul du bit de retenue sortante
srl $21, $17, 31 # Décalage pour extraire bit de poids fort
# $21 contient le flag de dépassement (overflow)
var: .word 0xFFFF0000 # Variable de test 32 bits
Concepts appliqués:
- Instructions arithmétiques:
addi: addition immédiate (avec constante)add/addu: addition signée / non signéemul: multiplication
- Instructions logiques:
and: ET bit à bitor: OU bit à bitxor: OU exclusif bit à bitnot: inversion (complément à 1)
- Instructions mémoire:
lw(load word): chargement 32 bits depuis mémoire- Directive
.word: déclaration de donnée 32 bits
- Instructions de contrôle:
j(jump): saut inconditionnel- Étiquettes pour les adresses
- Gestion du dépassement:
- Détection de l’overflow sur addition
- Utilisation de la logique booléenne pour calculer la retenue
- Formule:
Overflow = Cout XOR Cin(retenue sortante XOR entrante)
Analyse de l’algorithme de détection de dépassement
Principe mathématique:
Pour détecter un dépassement (overflow) sur addition:
c = a + b
e = a AND b (positions où a=1 et b=1, retenue garantie)
x = a XOR b (somme sans retenue)
Retenue sortante = (x AND NOT(c)) OR e
Si le bit de poids fort de la retenue = 1 → overflow
Exemple numérique:
a = 0xFFFF0000 (grand nombre négatif en complément à 2)
b = 0xFFFF0000
c = 0xFFFE0000 (résultat)
Analyse bit par bit du MSB (bit 31):
a[31] = 1, b[31] = 1
c[31] = 1
Overflow détecté si signe change incorrectement
Exercices de Calcul de Performances
Calcul du temps d’exécution
Formule fondamentale:
Temps_CPU = Nombre_instructions × CPI × Période_horloge
Où:
CPI = Cycles Per Instruction
Période = 1 / Fréquence
Exemple d’exercice:
Programme: 1 million d'instructions
CPI moyen: 2.5
Fréquence CPU: 2 GHz
Temps_CPU = 10^6 × 2.5 × (1 / 2×10^9)
= 2.5×10^6 / 2×10^9
= 1.25 ms
Performances du cache
Exercice type:
Cache L1: 32 KB, 4-way associative, ligne 64 octets
Hit time: 1 cycle
Hit rate: 95%
RAM:
Latence: 100 cycles
Calcul temps d'accès moyen:
T_moy = 0.95 × 1 + 0.05 × 100
= 0.95 + 5
= 5.95 cycles
Amélioration par rapport à sans cache:
Speedup = 100 / 5.95 = 16.8×
Calcul de pagination
Exercice de traduction d’adresse:
Configuration:
- Pages de 4 KB (4096 octets = 2^12)
- Adresses virtuelles 32 bits
- Adresse physique 30 bits
Adresse virtuelle: 0x12345678
Décomposition:
Bits 31-12: numéro page virtuelle = 0x12345
Bits 11-0: offset = 0x678
Si table des pages indique: VPN 0x12345 → PFN 0x00ABC
Adresse physique:
= (0x00ABC << 12) | 0x678
= 0x00ABC678
Optimisation du Code
Exploitation du cache
Mauvaise utilisation (cache miss fréquents):
// Parcours colonne par colonne (mauvaise localité spatiale)
for (int j = 0; j < N; j++)
for (int i = 0; i < N; i++)
sum += matrix[i][j]; // Accès non contigus
Bonne utilisation (cache friendly):
// Parcours ligne par ligne (bonne localité spatiale)
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
sum += matrix[i][j]; // Accès contigus
Explication:
- Les matrices en C sont stockées ligne par ligne (row-major order)
- Lignes de cache: 64 octets = 16 entiers (4 octets chacun)
- Parcours ligne → tous les éléments d’une ligne chargés ensemble
- Parcours colonne → chaque accès charge une nouvelle ligne de cache
Blocking/Tiling pour matrices
Technique de blocking:
// Multiplication matricielle avec blocking
#define BLOCK_SIZE 32
for (int ii = 0; ii < N; ii += BLOCK_SIZE)
for (int jj = 0; jj < N; jj += BLOCK_SIZE)
for (int kk = 0; kk < N; kk += BLOCK_SIZE)
// Bloc de BLOCK_SIZE × BLOCK_SIZE
for (int i = ii; i < min(ii+BLOCK_SIZE, N); i++)
for (int j = jj; j < min(jj+BLOCK_SIZE, N); j++)
for (int k = kk; k < min(kk+BLOCK_SIZE, N); k++)
C[i][j] += A[i][k] * B[k][j];
Avantage: réutilisation des données en cache L1 avant éviction
PART D: ANALYSE ET RÉFLEXION
Connaissances et compétences mobilisées
- Architecture des systèmes: compréhension profonde du fonctionnement matériel
- Programmation bas niveau: maîtrise de l’assembleur MIPS
- Optimisation: capacité à écrire du code efficace tenant compte du matériel
- Analyse de performances: calcul et optimisation des performances système
- Gestion mémoire: compréhension des mécanismes de pagination et cache
Auto-évaluation
Ce cours a été fondamental pour ma compréhension des systèmes informatiques. J’ai particulièrement apprécié:
Points forts:
- Lien théorie/pratique: les TPs en assembleur MIPS ont rendu concrets les concepts abstraits
- Compréhension du matériel: vision claire de ce qui se passe “sous le capot”
- Optimisation: capacité à comprendre pourquoi certains codes sont plus rapides
- Débogage: meilleure compréhension des erreurs (segfault, cache miss, etc.)
Difficultés rencontrées:
- Assembleur MIPS: syntaxe et conventions différentes du C
- Pipeline et hazards: concepts abstraits nécessitant de la visualisation
- Calculs de cache: nombreuses formules et cas particuliers
Applications pratiques:
- Optimisation de code pour systèmes embarqués
- Compréhension des contraintes temps réel
- Choix d’algorithmes adaptés à l’architecture
Mon opinion
Ce cours est indispensable pour tout ingénieur en informatique ou systèmes embarqués. Même à l’ère des langages de haut niveau, comprendre l’architecture matérielle permet:
- Meilleure performance: code optimisé pour le cache et le pipeline
- Debugging efficace: comprendre les erreurs mémoire, les ralentissements
- Choix techniques: sélectionner le bon processeur pour une application
- Embarqué: conception de systèmes avec contraintes strictes
Connexions avec autres cours:
- Systèmes d’exploitation (S5): gestion mémoire virtuelle, ordonnancement
- Microcontrôleur (S6): application pratique sur STM32
- Temps Réel (S8): contraintes de timing liées au matériel
- Systèmes embarqués (S7): optimisation pour ressources limitées
Évolution des architectures:
Aujourd’hui, les défis ont évolué:
- Multiprocesseur: parallélisme, cohérence cache complexe
- Hétérogène: CPU + GPU + accélérateurs (TPU, NPU)
- Mémoire non-volatile: nouvelles technologies (3D XPoint, ReRAM)
- Sécurité: Spectre, Meltdown → compromis performance/sécurité
La loi de Moore ralentit, mais l’innovation continue:
- Architecture 3D (empilement)
- Mémoires proches du calcul (in-memory computing)
- Architectures neuromorphiques
- Calcul quantique (futur)
Recommandations pour bien réussir:
- Pratiquer l’assembleur: écrire du code MIPS, analyser le désassemblage C
- Visualiser: dessiner les pipelines, les caches, les tables de pages
- Calculer: faire et refaire les exercices de performances
- Lire les spécifications: datasheets de processeurs (ARM, x86)
- Profiler: utiliser des outils (perf, valgrind) pour observer le cache
Applications professionnelles:
Ces connaissances sont utilisées dans:
- Développement de compilateurs: optimisations machine-spécifiques
- Systèmes d’exploitation: schedulers, gestionnaires mémoire
- Jeux vidéo: optimisations poussées pour FPS élevés
- HPC (High Performance Computing): supercalculateurs
- IoT: microcontrôleurs à ressources limitées
- Automobile: ECU temps réel critiques
- Sécurité: analyse de vulnérabilités hardware
En conclusion, ce cours fournit les bases essentielles pour comprendre comment le logiciel interagit avec le matériel. C’est un investissement qui porte ses fruits tout au long de la carrière, car les principes fondamentaux (hiérarchie mémoire, pipeline, cache) restent valables même si les technologies évoluent.
📚 Documents de Cours
Voici les supports de cours en PDF pour approfondir l’architecture informatique matérielle :
📖 Introduction aux Architectures
Vue d'ensemble des architectures informatiques, évolution historique et concepts fondamentaux.
💾 Mémoire Physique
Organisation de la mémoire physique, types de mémoires (RAM, ROM, Flash) et hiérarchie mémoire.
🗺️ Mémoire Virtuelle
Gestion de la mémoire virtuelle, pagination, segmentation et traduction d'adresses.
⚡ Mémoires Caches
Fonctionnement des caches, politiques de remplacement, cohérence des caches et optimisation des performances.
🖥️ Processeur
Architecture du processeur, pipeline, parallélisme d'instructions et optimisations matérielles.